Hierarchy: experiment, job, trial
Three concepts, nested:
You don’t usually think about jobs in CoPilot mode. The hierarchy matters most in Scientist mode, where you create jobs one at a time.
Regression vs classification
The type of your target property determines whether the experiment is a regression or a classification problem. You don’t choose this manually.
This affects:
- Which algorithms are available
- Which metrics are reported
- How results are visualized
CoPilot vs Scientist
Two modes for building models, set when you create the experiment.
You can’t switch modes after creation. If you change your mind, create a new experiment.
Experiments page
Go to Experiments in the project sidebar.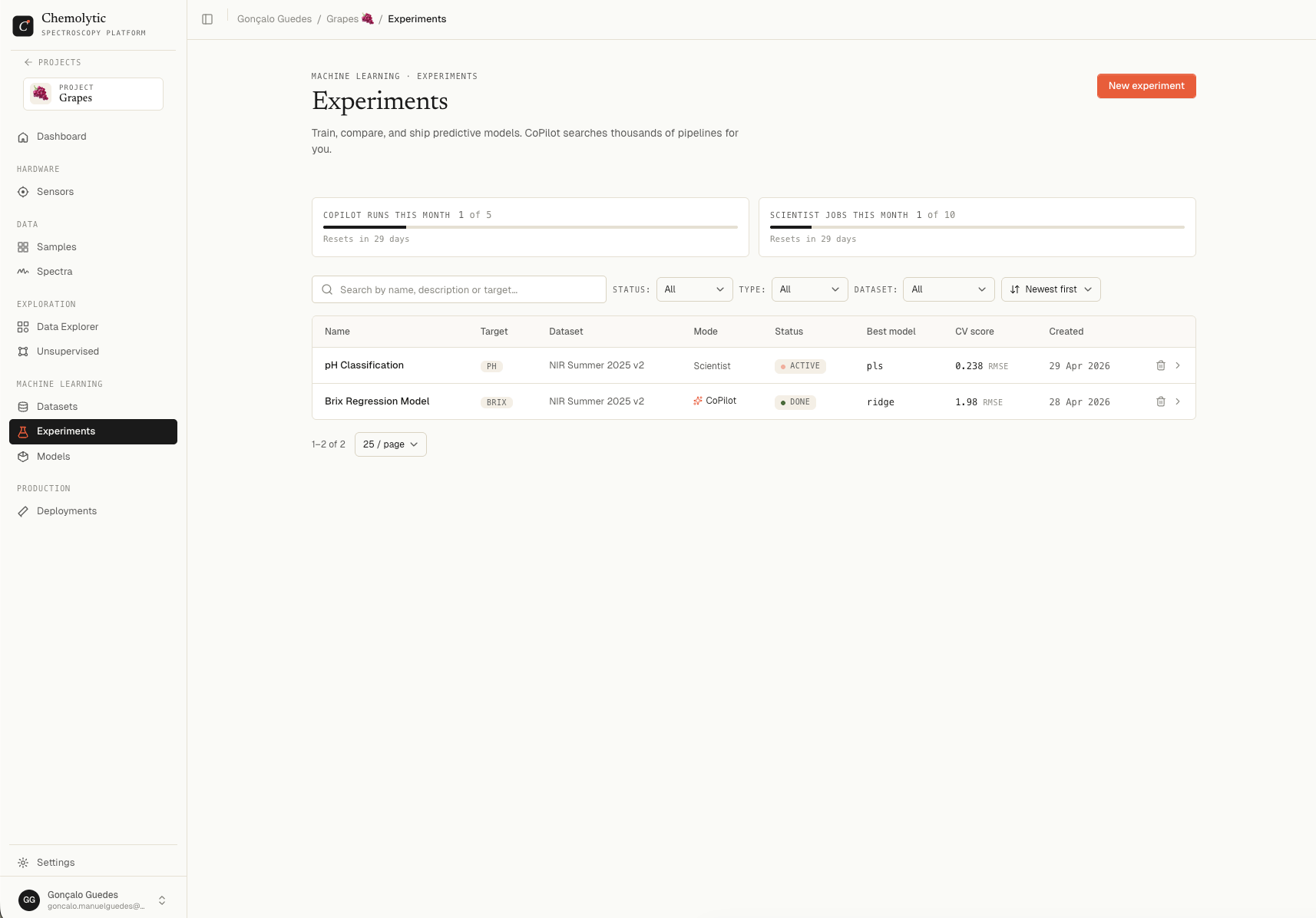
Filters
The list polls every 3 seconds when any experiment is running, so progress updates live.
Status badges
Plan limits
Two monthly quotas, shown at the top of the Experiments page:
Both reset at the start of your billing period. The widget shows when the next reset happens.
If you hit a quota mid-month, you can still browse and inspect existing experiments; only creating new ones is blocked.
Deleting an experiment
Click the trash icon on a row, or the Delete action in the detail page.What’s next
- Creating an experiment for the create flow
- CoPilot mode for automated model search
- Scientist mode for hands-on configuration
- Trial results for reading metrics and registering models