Tabs in the trial modal
The Results tab
Pipeline section
Visual representation of what was trained:Performance toggle: CV vs Test
The metric grid below the pipeline switches between two evaluations:
Always check both. If CV looks great but Test is much worse, the model overfit. If both are similar, the model is solid.
Regression metric grid
Classification metric grid
Predicted vs Actual (regression)
Scatter plot with one point per sample.- The diagonal line is the ideal: predicted value equals actual value
- Points close to the line = good predictions
- Points far from the line = errors
- A wide cloud = high noise; a tight diagonal cloud = strong model
Confusion matrix (classification)
Table where rows are actual classes and columns are predicted classes. Cell colour indicates count (darker = more predictions).The Details tab
Shows the exact configuration used:- Trial # and Duration (training time in seconds)
- Model parameters with each hyperparameter value
- Preprocessing parameters for any step that has them
Comparing trials in the leaderboard
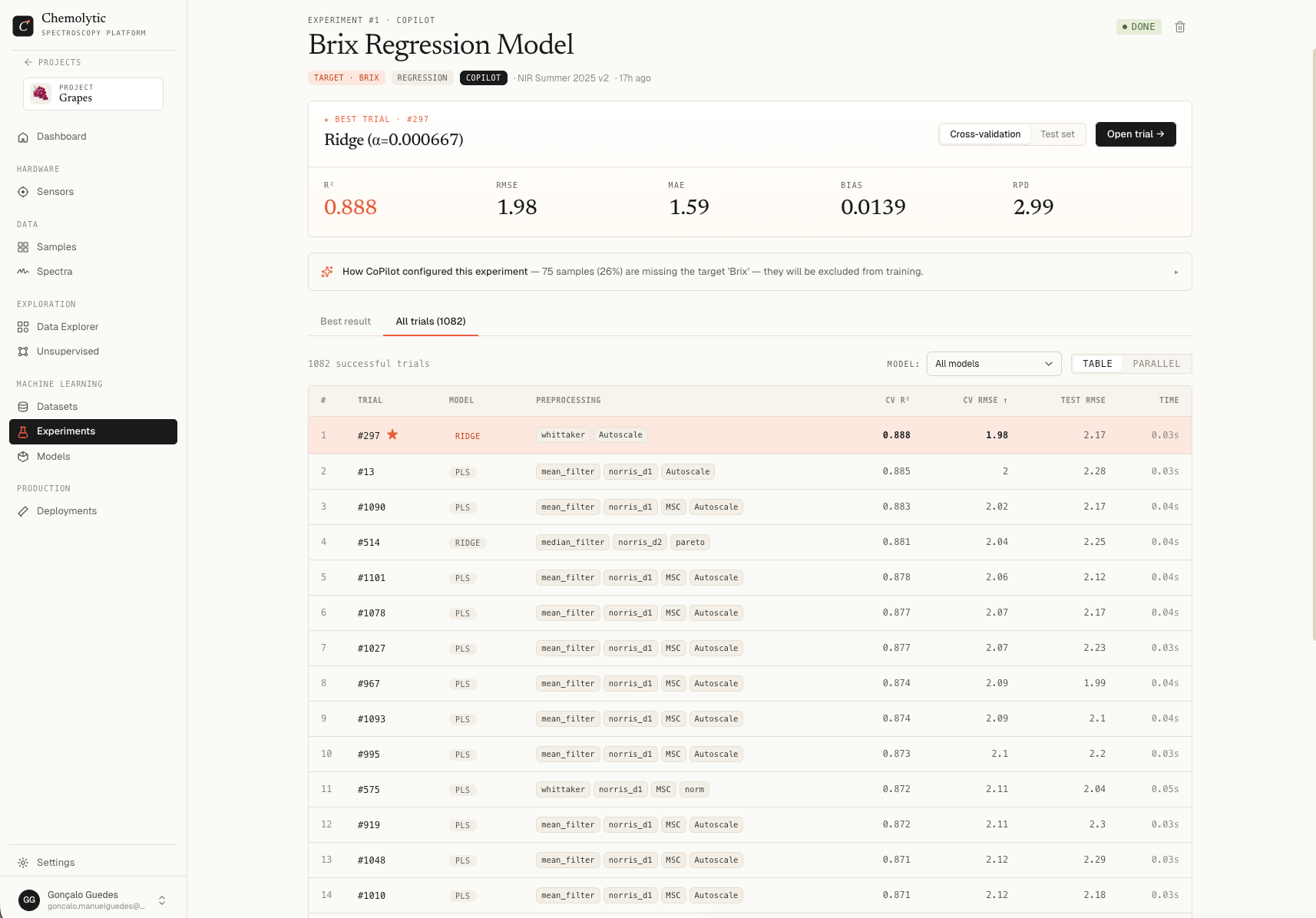
Before drilling into one trial, you usually want to compare many. The All trials tab on the experiment detail page shows every trial across every job, with two view modes.Table view
A standard sortable table with one row per trial.
The best trial is highlighted with a flame-coloured row and a star (★).
Click any column header to sort. Click a row to open the trial detail modal.
Filters and pagination
- Model filter: dropdown to limit the table to one model family (e.g., only PLS trials). Useful when you have hundreds of trials across many models.
- Page size: 25, 50, 100, or 250 per page.
- Counter: shows “X-Y of Z” with a “(filtered)” suffix when the model filter is active.
Parallel coordinates view
Toggle from Table to Parallel at the top right.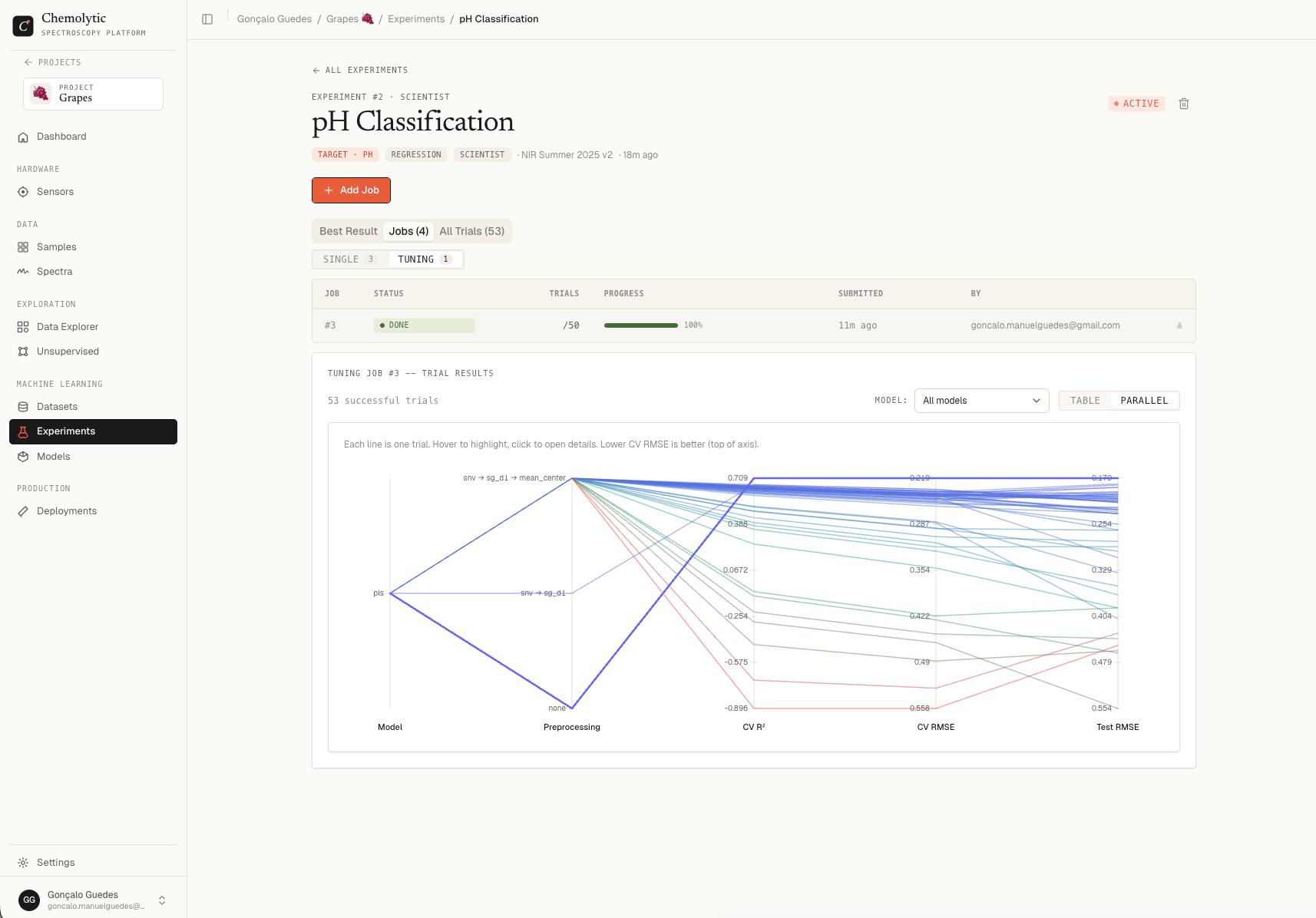
- Each line is one trial
- Each vertical axis is one parameter or metric (model family, preprocessing choice, hyperparameter values, CV metrics, test metrics)
- Lines move from left to right, connecting that trial’s value on each axis
- Better metrics are oriented so “down” is always good (or “up”, labelled at the top of each axis)
What this view is good for
Interaction
- Hover any line to highlight it; other lines fade
- Click a line to open the trial detail modal
- The legend at the top of each axis tells you whether higher or lower is better
Per-job leaderboards (Scientist mode)
Inside the Jobs tab, clicking an expanded tuning job row reveals the leaderboard for just that job’s trials. Same table and parallel views, scoped to a single job. Useful when you’ve run multiple tuning jobs with different parameter spaces and want to evaluate them independently.Registering a model
Click Register Model at the bottom of the modal. A footer panel opens.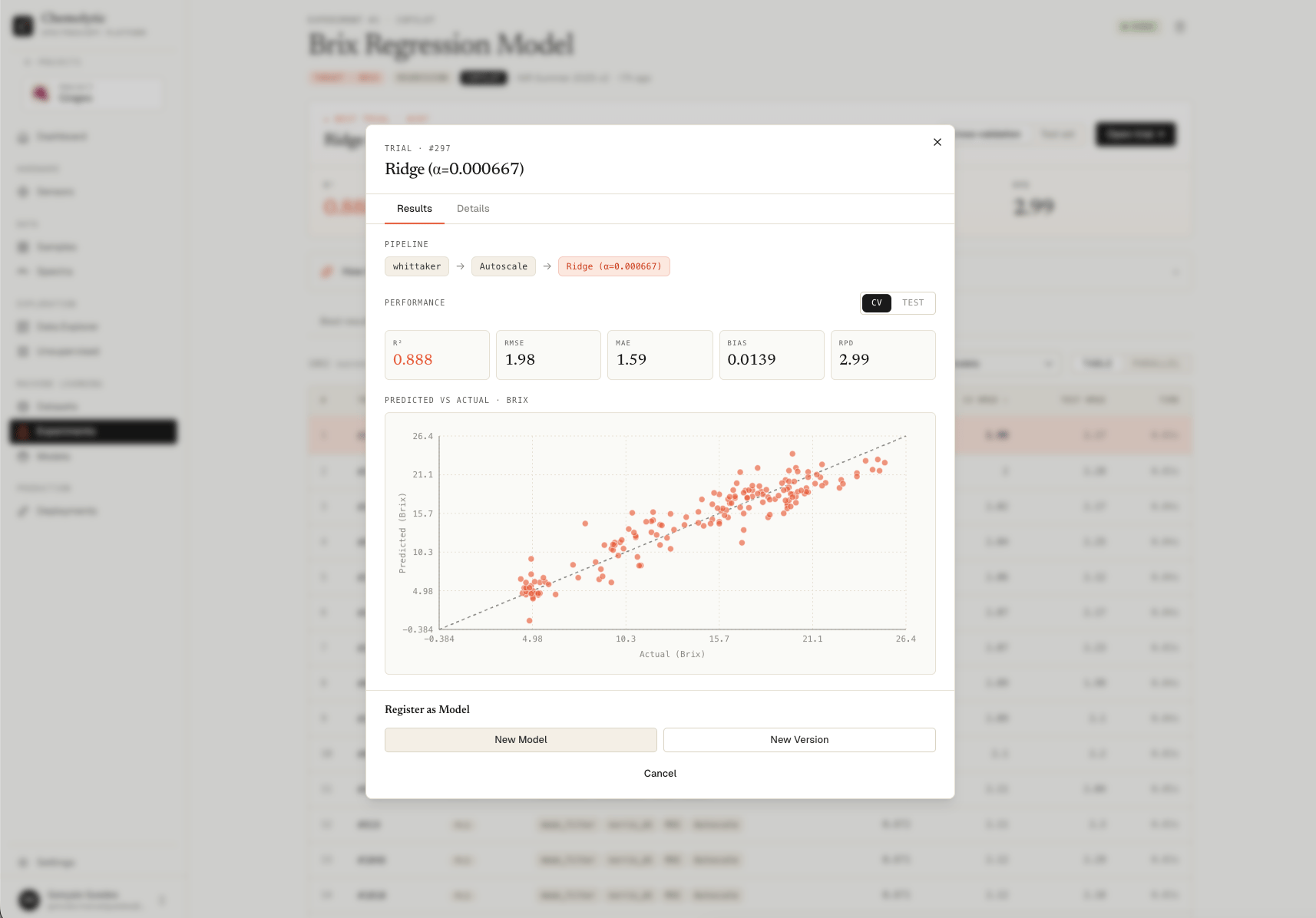
New model vs new version
You’re given two options:New model
Click Register. The trial is refit on the full training set (no CV split) and saved as v1 of the new model.
New version
A confirmation step appears: “This will create a new version of '' using trial #. The model will be refit on the full training set.”
Click Create Version. The trial is refit on the full training data and saved as the next version (v2, v3, …).
What happens after registration
The trial is permanently saved as a registered model. From there you can:- View it in the Models page
- Deploy it for live predictions
- Compare versions across the model’s history