Analysis vs run
The unsupervised feature has two levels:
You typically create one analysis per investigation (e.g., “NIR Spring 2026 baseline”), then make several runs inside it to try different preprocessing and methods.
Creating an analysis
Click New analysis on the Unsupervised page.
You can only create an analysis on a sensor that already has spectra uploaded.
Click Create analysis to land on the detail page.
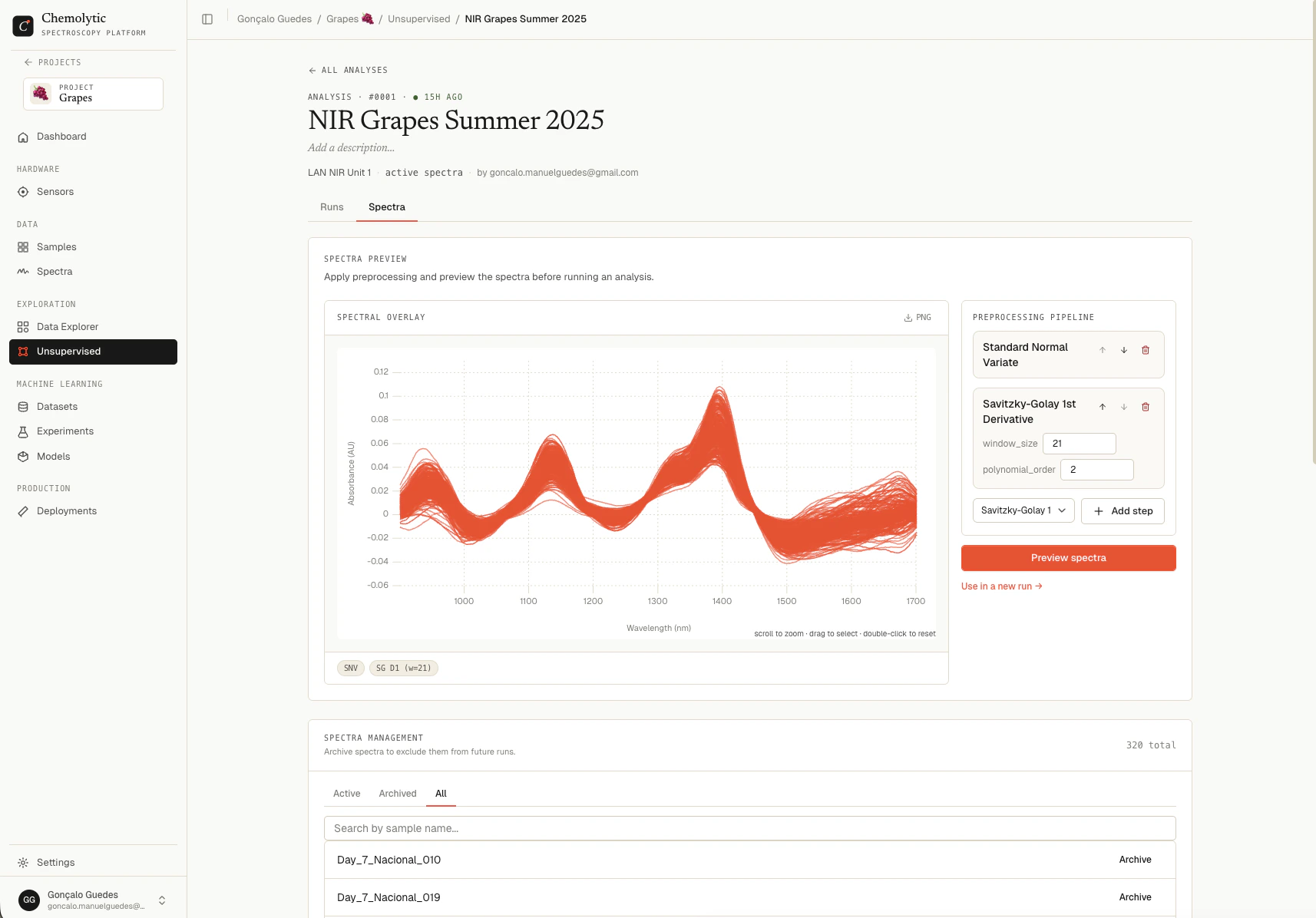
Analysis detail page
The detail page has three main sections:- Spectra preview: apply preprocessing and visualize the resulting spectra before committing to a run
- Configure run: pick a method and parameters, then launch
- Runs list: see all runs in this analysis, their status, and open them
Spectra preview
Before committing to a run, you can interactively apply preprocessing and watch the spectra change. This is the fastest way to find a pipeline that brings out the structure in your data. The Spectra preview card has two parts:- Spectral overlay chart on the left: every active spectrum overlaid
- Preprocessing pipeline sidebar on the right: the catalog of methods you can apply
Building a pipeline
The pipeline is a list of preprocessing steps, applied in order. Each step’s output feeds the next step’s input.1
Pick a method from the catalog
The catalog groups methods by category (Smooth, Baseline, Scatter, Derivative, Scale). Click a method to add it to the pipeline.
2
Reorder steps if needed
Drag a step up or down to change the order. Order matters: SNV → SG D1 produces a different result than SG D1 → SNV.
3
Preview the result
Click Preview spectra. The chart updates to show your spectra after the pipeline is applied. The original raw spectra are not modified.
4
Iterate
Add, remove, or reorder steps and preview again. There’s no cost to previewing as many combinations as you want.
Reading the chart
The preview chart shows all active (non-archived) spectra overlaid. Hover any line to highlight it. The x-axis uses the sensor’s units (e.g., nm or cm⁻¹), the y-axis depends on the last step in the pipeline (e.g., absorbance for raw or SNV, derivative units for SG D1). What to look for as you tweak the pipeline:Available methods
Categories are mostly exclusive: you typically use one method per category. The UI prevents you from adding two baseline methods to the same pipeline, for example.
Common pipelines
From preview to a run
When the preview looks good, click Use in a new run → at the bottom of the preview card. This carries the pipeline directly into the Configure run form below, so you don’t have to rebuild it. Pick a method, set parameters, and launch.Spectra management
You can archive specific spectra to exclude them from future runs (useful for outliers identified by PCA). The archive list on the detail page mirrors the global Spectra page but scoped to this analysis. Archived spectra do not participate in new runs but the existing runs that already used them remain unchanged.Plan limits
Your plan limits the total number of analyses you can have. The current count and limit appear on the Analyses page. If you’ve reached the limit, delete an analysis you no longer need before creating a new one.What’s next
Now that you’ve configured a preprocessing pipeline, choose a method:- PCA for variance and outlier detection
- t-SNE for 2D cluster visualization
- K-Means to group samples into N clusters
- Comparing runs when you have multiple runs to compare