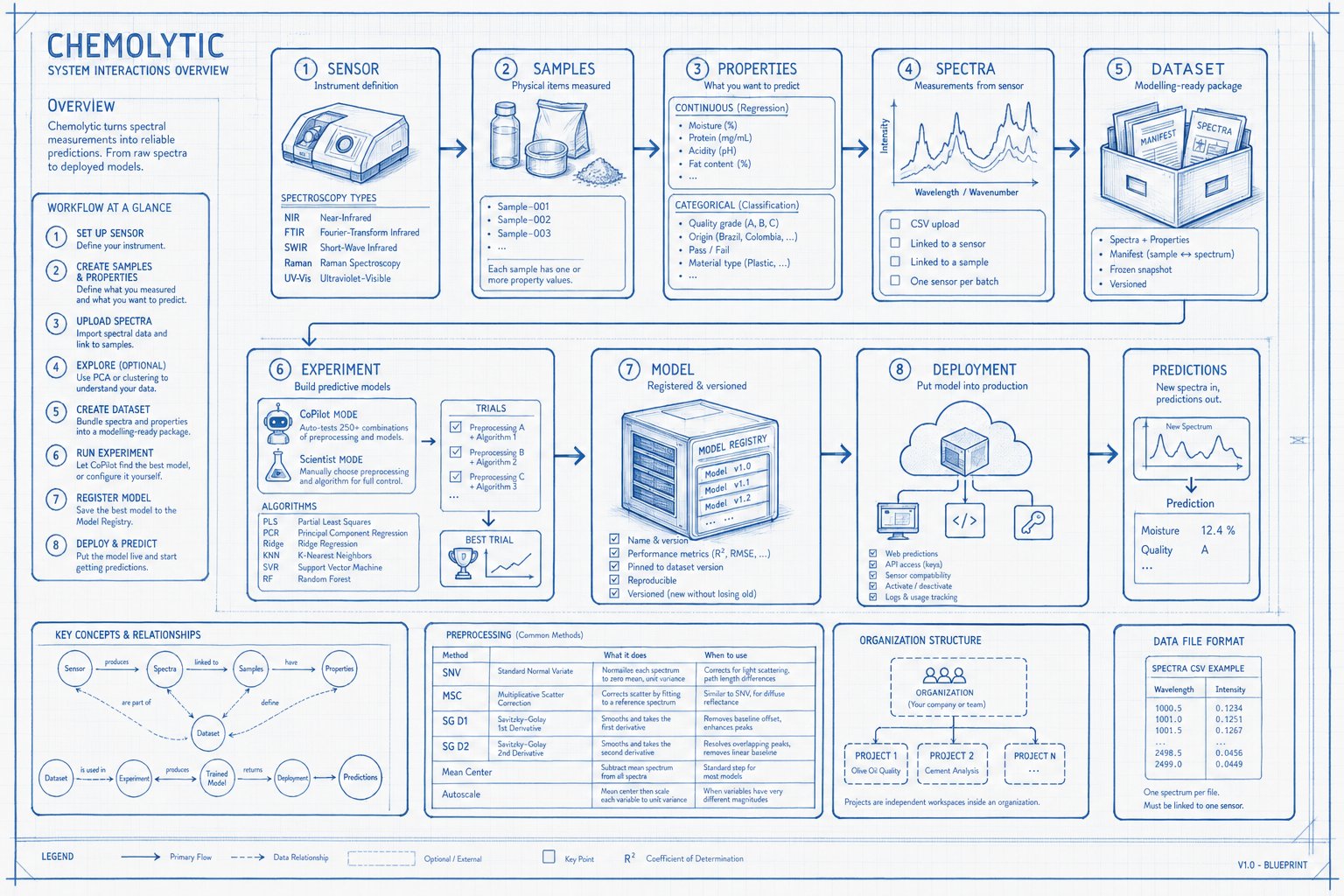
Organizations and projects
Organizations are your top-level workspace. Think of them as your company or team. Every user gets a personal organization when they sign up. Projects live inside organizations. Each project is an independent workspace for a specific use case: “Olive Oil Quality”, “Cement Analysis”, “Polymer Identification”.
Sensors
A sensor represents the physical spectrometer you used to measure your samples. Chemolytic needs to know about your sensor because:- Different sensors produce spectra with different wavelength ranges and number of data points
- Spectra from different sensors are not directly comparable
- When deploying a model, it must know which sensor produced the input spectra
You can pick a sensor from the catalog (pre-configured) or create a custom one with your own specifications.
You don’t need to understand the physics of spectroscopy to use Chemolytic. Just pick the type that matches your instrument.
Samples
A sample is a physical item you measured: an olive oil bottle, a soil core, a tablet, a grain batch. Each sample has:- A name (e.g., “Sample-001”)
- An optional description
- One or more property values (the things you want to predict)
Properties
Properties are the characteristics of your samples that you want to predict from spectra. There are two types:Continuous properties
Numeric values on a scale. Examples:- Moisture content (%)
- Protein concentration (mg/mL)
- Acidity (pH)
- Fat content (% w/w)
Categorical properties
Discrete categories or labels. Examples:- Quality grade (A, B, C)
- Origin (Brazil, Colombia, Ethiopia)
- Pass/Fail
- Material type (Plastic, Metal, Wood)
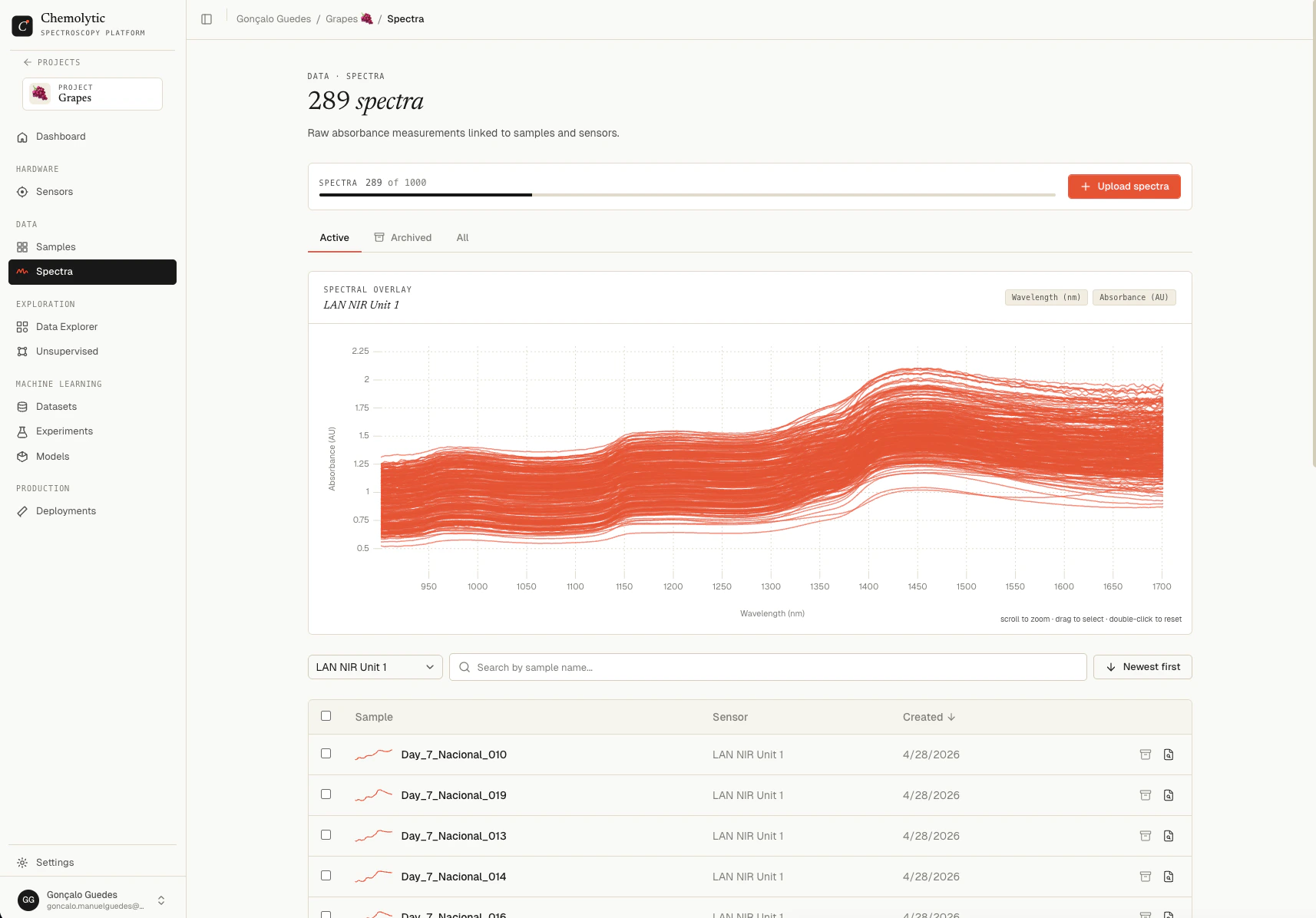
Spectra
A spectrum is the measurement output from your sensor for a given sample. It’s a series of intensity values across wavelengths or wavenumbers, essentially a curve. In Chemolytic, spectra are:- Uploaded as CSV files
- Always linked to a sensor (so Chemolytic knows the x-axis scale)
- Linked to a sample (so Chemolytic knows which physical item was measured)
- Visualized as interactive line charts
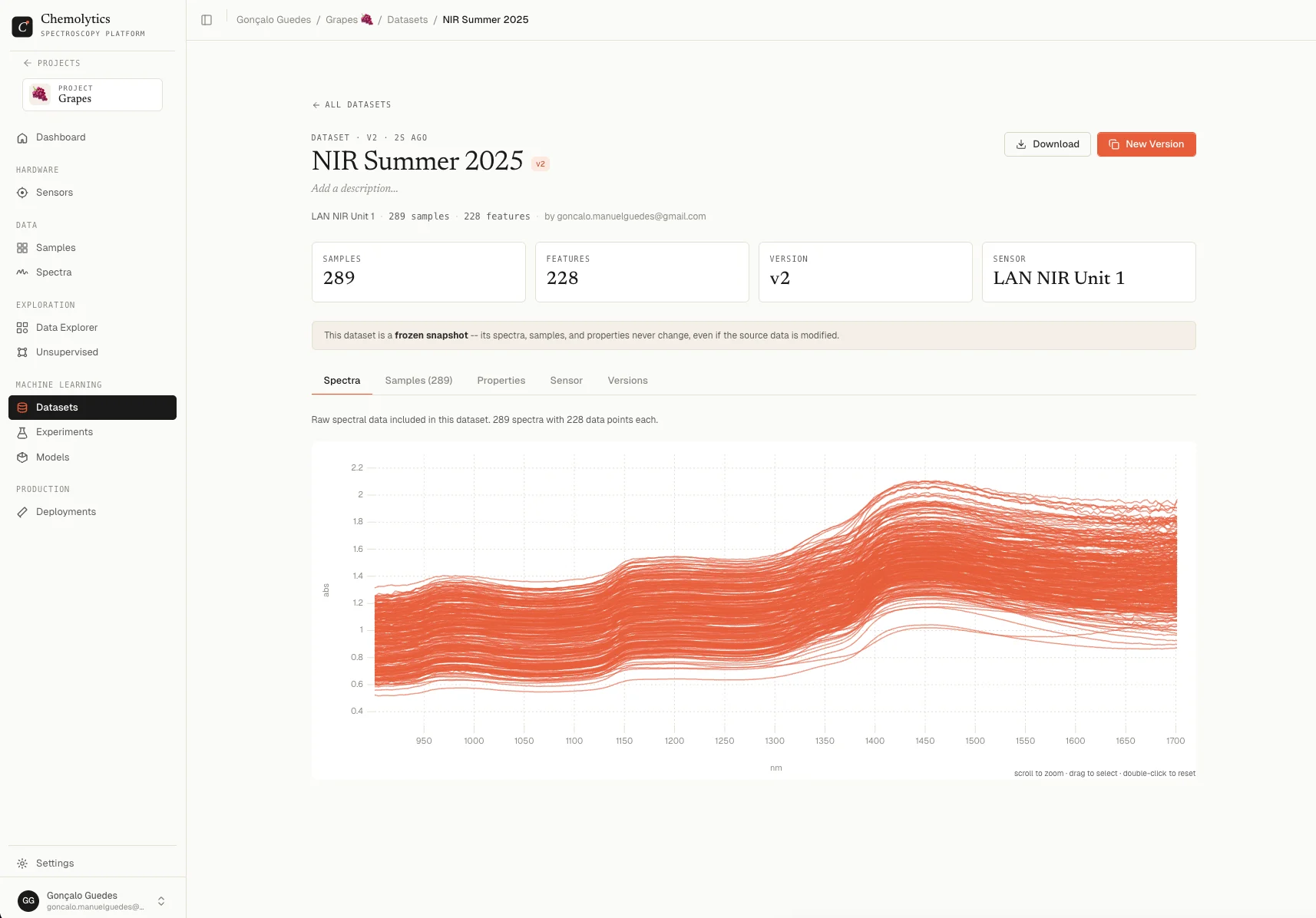
Datasets
A dataset is a packaged collection of spectra and sample properties, ready for modelling. Think of it as the “input” to an experiment. When you create a dataset, Chemolytic:- Takes spectra from a specific sensor
- Matches them with their sample properties
- Creates a manifest (a table showing which spectrum pairs with which sample and property values)
- Freezes this snapshot so your experiment results are reproducible
Preprocessing
Raw spectra often contain noise, baseline drift, or scaling differences. Preprocessing cleans and transforms spectra before modelling.Experiments
An experiment is where you build predictive models. You give it a dataset and a target property, and it produces trials. Each trial is one model trained with a specific preprocessing pipeline and algorithm.Two modes
Available model algorithms
Models
When an experiment finishes, you can register the best trial as a named model in the Model Registry. Registered models:- Have a name and version number
- Track their performance metrics (R², RMSE, accuracy, etc.)
- Pin to the dataset version they were trained on for reproducibility
- Can be deployed as prediction endpoints
- Support versioning: train a new version without losing the old one
Deployments
A deployment puts a registered model into production. Once deployed, you can:- Send new spectra and get predictions back instantly via the web interface
- Generate API keys for programmatic predictions
- Track which sensors the deployment supports
- Activate/deactivate without deleting the deployment or its logs
The full workflow
1
Set up your sensor
Tell Chemolytic what instrument you’re using.
2
Create samples and properties
Define what you measured and what you want to predict.
3
Upload spectra
Import your spectral data files and link them to samples.
4
Explore (optional)
Run PCA or clustering to understand your data before modelling.
5
Create a dataset
Bundle spectra and properties into a modelling-ready package.
6
Run an experiment
Let CoPilot find the best model, or configure it yourself in Scientist Mode.
7
Register the best model
Save it to the Model Registry for tracking and deployment.
8
Deploy and predict
Put the model live and start getting predictions on new data.